
Rodolfo M. Raya (rmraya@maxprograms.com)
Chief Technical Officer, Maxprograms
Rodolfo M. Raya (rmraya@maxprograms.com)
Chief Technical Officer, Maxprograms
This article was enhanced by the DITA Adoption TC at OASIS and the official version is available in PDF format from OASIS and in HTML format at ditatranslation.com
DITA (Darwin Information Typing Architecture) is an XML-based architecture for authoring, producing, and delivering information published by OASIS (Organization for the Advancement of Structured Information Standards). The authoring model followed by DITA differs with the traditional book-oriented model of documentation writing. In the DITA authoring model focus is given to topics, small pieces of information that are then connected using special maps and several mechanisms that allow text reutilization.
DITA promises cost reduction thanks to content reuse. With careful planning, costs can indeed be lowered. Cost reduction depends on project nature and it is not possible to predict reduction percentages in advance. Content reuse can lead to translation costs reduction when proper planning is done.
Ideally, you should never pay twice for the translation of your content. Real world is not perfect, but with careful selection of tools and strategies, you can get excellent results.
If you share DITA topics in the different DITA maps that make up your projects, you can also reuse the translations of those topics.
XLIFF (XML Localization Interchange File Format) is an open standard published by OASIS (like DITA) that you can use in your project workflow to manage the material that needs to be translated.
The XLIFF vocabulary has a rich set of elements and attributes that permit XLIFF-supporting applications to:
The XLIFF standard was first published by OASIS in 2002. Most modern translation environments currently support it. A Language Service Provider (LSP) using up to date tools should be able to accept XLIFF files that you pre-process in house.
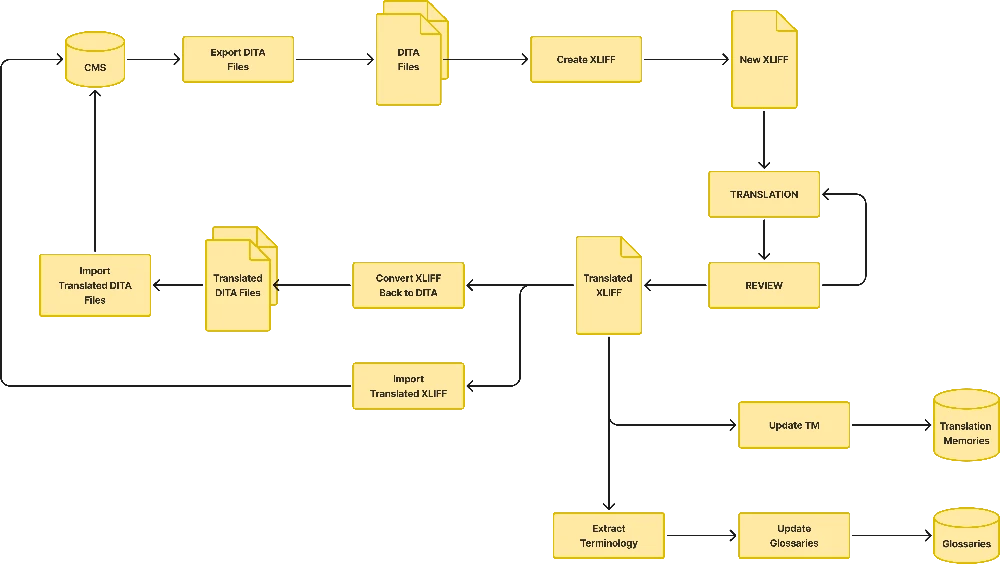
Write your DITA topics, prepare your maps and publish initial drafts. Refine your content as necessary, until you are satisfied with the published results.
Once your project is ready for translation, convert your maps to XLIFF format using a translation tool that supports DITA.
A translation tool that supports DITA should be able to:
Send the XLIFF file and a PDF rendering to your LSP. LSP’s translators will need the PDF for translating with context.
After receiving the translated XLIFF file, convert it to original format. As result, you should obtain a directory structure identical to the original one. If your images were not in SVG format, you will have to copy them to the new project structure before you can render the translated project in PDF or other formats.
Export the translations in your XLIFF file to TMX (Translation Memory eXchange) format and update your Translation Memory. Store the translated XLIFF and the TMX file in your content repository. Both files will play a crucial role in the maintenance cycle.
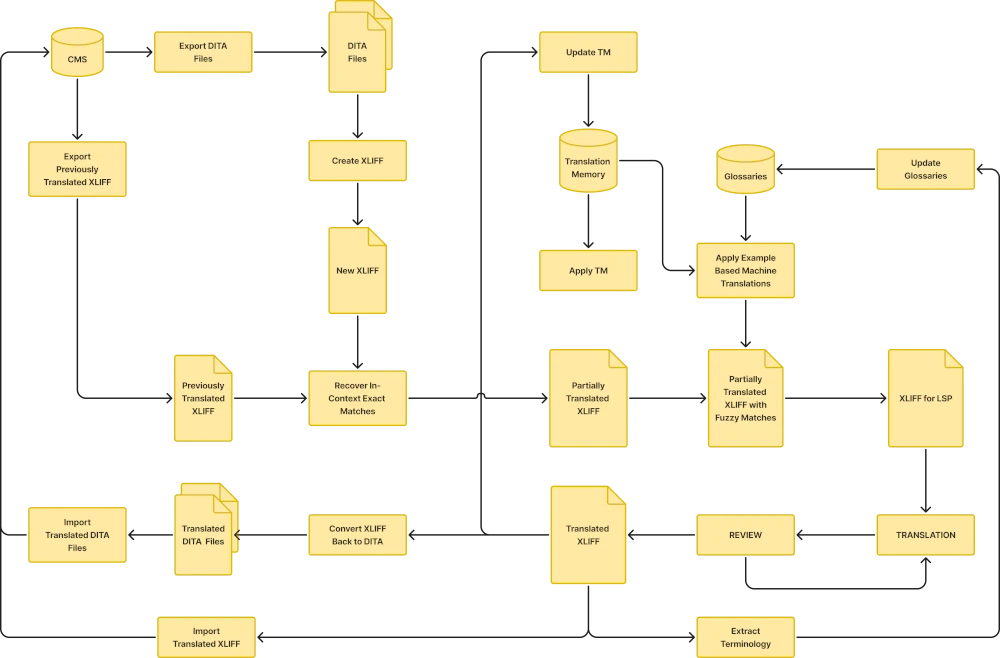
As time passes, you will update some of your topics, write new ones and the time to update translations will come. When it happens, you will see the benefits of translation reuse with these techniques:
Start by converting the updated DITA project to XLIFF. Next, let your translation tool compare the new XLIFF with the one you translated before and recover In-Context Exact (ICE) matches. This will let you recover translations of text that has not changed since last translation cycle.
After recovering all ICE matches, mark all translated segments as untranslatable. Translations will remain visible in the XLIFF as context information for the translator but they don’t need to be changed.
Next step requires the TMX file obtained in the previous translation cycle. If you have not yet updated your Translation Memory with the translations of the previous cycle, import the TMX into the Translation Memory of your translation environment and use the TM engine to retrieve matches for the segments that remain untranslated.
A TM engine can evaluate the similarity between current text requiring translation and entries that exists in its database. Entries identical to the text being translated are considered 100% matches; entries that have some differences with the searched text are called fuzzy matches.
If your translation memory only contains entries from a very similar project, you may want to accept all 100% matches as final. There is no guarantee that those matches are the right translations, so you should let professional translators approve them. Nevertheless, you may ask your LSP to set a special price for segments with good matches from your own TM.
Use Example-Based Machine Translation (EBMT) and recover extra matches. Sometimes the difference between old text and the new one is just an updated number and that is something a good CAT (Computer Aided Translation) program can correct automatically using EBMT techniques. An EBMT engine can also automatically correct the translation of known terms with the aid of a terminology database.
After following all previous steps you should have an XLIFF file ready for sending to an LSP for completing the translation cycle. Send it with an updated PDF rendering and remember to update your TM engine when you receive the translated version back.
Finally, if your translation budget allows it, generate a PDF rendering of the translated project and send it with a copy of the translated XLIFF to your LSP for proofreading. If the reviewer finds an error, it can be corrected in the XLIFF file and sent back to you for updating your topics.
It is usually very useful to prepare glossaries and provide them to your LSP. This helps in keeping consistency for special terms. Ask your LSP to provide translated versions of your glossaries; you can use them with your EMBT engine.
You can translate DITA maps or individual topics using XLIFF as intermediate format. When translating DITA maps it is very important to use a tool that can handle the different content linking mechanisms offered by DITA. It is not necessary to resolve referenced content when translating individual topics, but you can still make good use of the translation reuse strategies described above.

Rodolfo Raya is Maxprograms' CTO (Chief Technical Officer), where he develops multi-platform translation/localisation and content publishing tools using XML and Java technology. He can be reached at rmraya@maxprograms.com.